Slash
Teaching neural networks how to rock n' roll

Satyaki Chakraborty
(
shady-cs15
)
May 2017
Neural networks are being used extensively these days as generative models. In the domain of audio generation, recurrent nets have proved to be an essential tool for artifical audio synthesis primarily because of the sequential structure of audio data. Here is an amazing blog post from Google Magenta on generating long term structures in songs (in MIDI form) with RNNs. However, two recent breakthroughs in audio generation have dealt with audio in its rawest form i.e. wave form. One is Google's Wavenet and the other one is MILA's Samplernn. Since both the inputs and the outputs of the networks are raw waves(quantized), I wanted to see whether they can be used to generate polyphonic music like rock n' roll solos. And hence project slash!
Networks trained on raw waves do not make any assumption of the data on which they are trained, which means, this
very same network that has been trained on a guitar music dataset to generate guitar solos can be used for generating human speech just by training
it on some speech dataset. Also unlike MIDI files, raw audio data is easily and abundantly available on the internet and doesnot require any high level
transcription.
Now the cons! Sampling rate for a studio grade experience is usually 44.1 kHz, which means there are 44,100 samples in just one
second of audio data. So, for generating just 5 seconds of audio data we need to generate 44,100 x 5 = 220,500 samples. Not only does this
make the training time longer by significant proportions, capturing long term dependencies is now more difficult than ever.
Let's start by taking a look at some of the samples generated by the neural network.
These samples were generated after training the neural network on some of Slash's iconic guitar solos for 100,000 iterations (more than a week of GPU time). Samples have not been edited in any way.
This is a very common question everyone has in mind while working with raw audio waves. To be honest, the answer very much depends on the type of dataset you are working on. My guess is at 10k - 20k iterations, it starts to generate some music, but the tone is really noisy. At around 70k - 100k iterations, the tone gets cleaner, however, some of the samples generated can still be noisy to some extent. Here is a video showing the samples generated by the network over time.
The architecture that I developed is mostly based on that of Samplernn's (with some minor modifications here and there). Most of the reasons why I opted for this model is described in this blog post. But before we go into the details of the architecture of this model, let's first take a step back and try to figure out how we would use a simple RNN to generate raw audio waves.
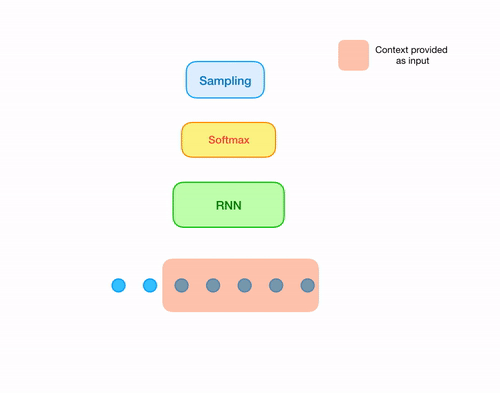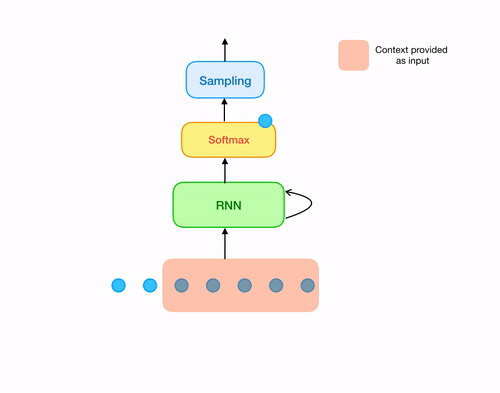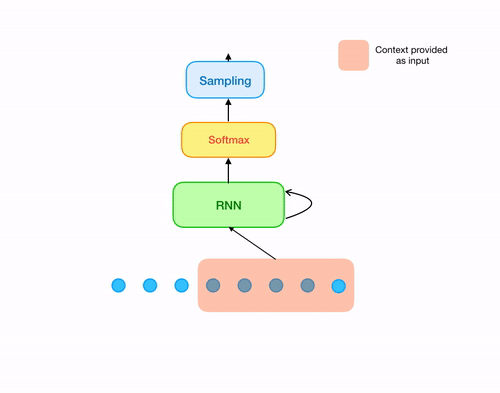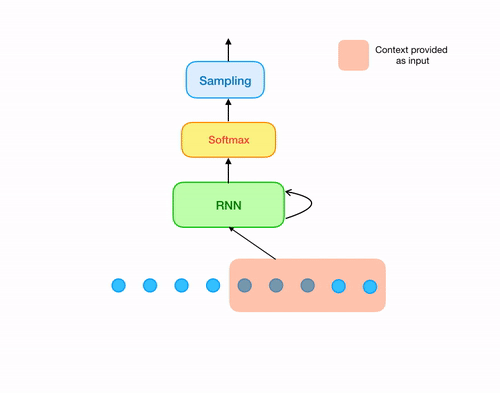
Note that, at every time step we feed a portion(window) of the raw audio wave to the network to generate a sample and then
slide the window by one sample to the right. We can repeat this process for several times to generate a sequence of samples,
and thereby form an audio wave. But there is some significant redundancy with this approach. Let the input to the RNN at every time
step be denoted by xt. Then, xt and xt+1 have significant overlap (overlap of window length - 1).
Not just that! Since we produce only one sample per output of the recurrent cell, we will need quite a significant number of iterations
to generate even one second of audio data (no. of iterations = sampling rate). Thus capturing long term dependency in this case
is a huge issue.
Now we are slowly moving towards building the sampleRNN architecture. Point to note: What we don't want is overlapping windows!
So, at every iteration, we now slide the window by the length of the window to the right, in stead of sliding it by just one sample.
And since, we are doing that, now at every iteration, we need to generate the next window of samples in stead of just generating the
immediately next one.
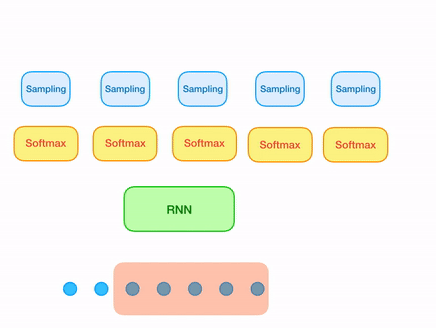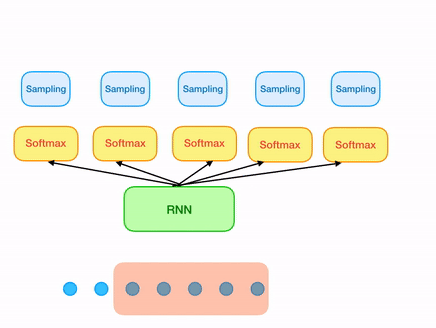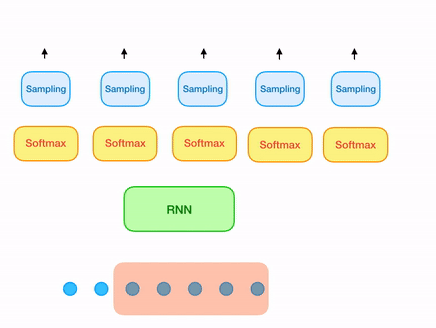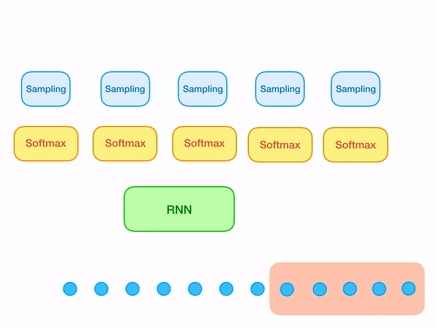
Now let's come to the original samplernn 2-tier architecture. The previous approach solves our issue of overlapping windows. But still there is something missing. A sample that is being generated, most of the time is unaware of the sample (or series of samples) just preceeding it, unless it is the first sample of the window being generated. In order to solve this, all we need is one small modification in our architecture. For every sample that is being generated, use both the output from the RNN cell as well its local context(context of last n samples corresponding to the sample being generated).
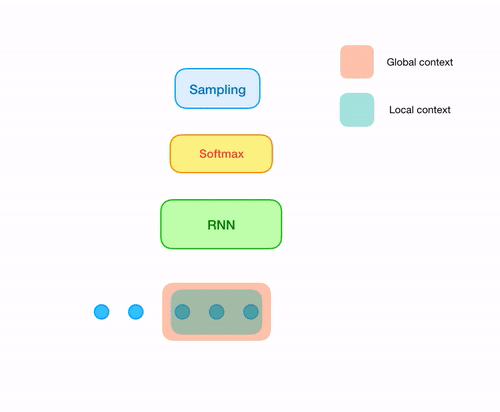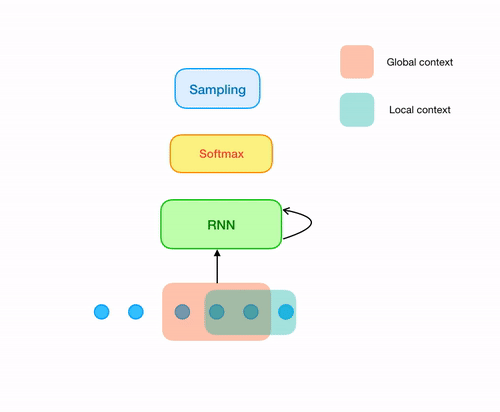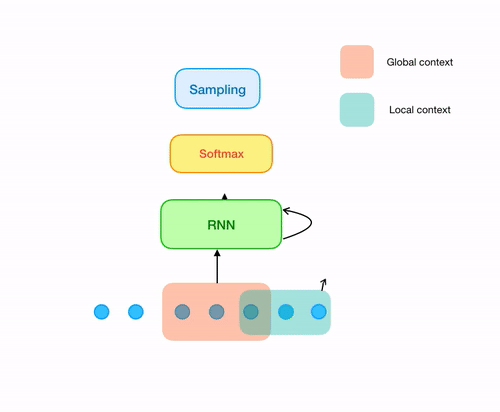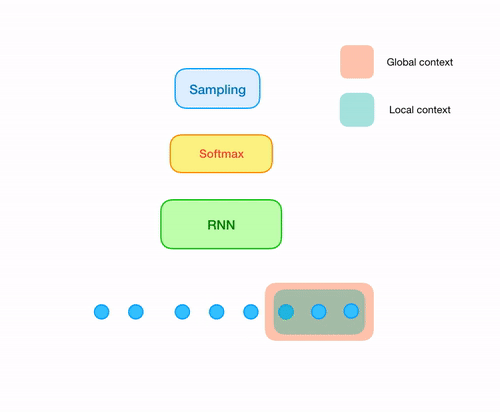
Obviously, the actual architecture isn't just softmax after one recurrent layer. The version that I implemented in tensorflow has 3 recurrent(LSTM) layers, followed by 3 MLP layers(along with downsampling and softmax), each of the layers having 1024 neurons. The architecure is implemented in src/model.py. Also note that, the architecture that I've discussed here is the 2-tier model of samplernn. There is a also a 3 tier version that uses recurrent layers operating at two different clock rates. For more details, refer to their original paper.